Research
I work at the intersection of AI and quantum computing — developing the theory for when quantum models genuinely help, and building the AI tools that make today's quantum computers more useful. In brief, my research runs along three connected threads 👇

① Quantum Learning Theory
Quantum computers are powerful — but when does a quantum AI model actually beat a classical one, and when is it just hype? This thread builds the rigorous answers: what quantum models can learn, how much data they need, and where their real limits are. Think of it as the "physics of quantum machine learning." 🔬

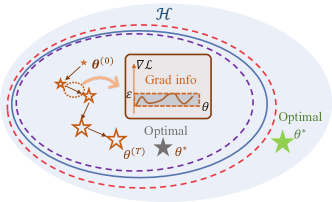
Among the first to give the expressivity of variational quantum circuits a rigorous, computable yardstick. Using covering numbers from learning theory, we tied a model's "reach" directly to gate count, circuit depth, and noise — turning a fuzzy notion into a practical design knob. Physical Review Letters, 2022. [paper]

The first unified framework for when quantum classifiers win on multi-class tasks. We folded a whole zoo of quantum classifiers into one model and found the answer depends on the data — they shine on quantum data with very few examples, but lose to classical models on everyday data like images, even in the best case. A reality check, and a map for where to hunt real advantage. [paper]
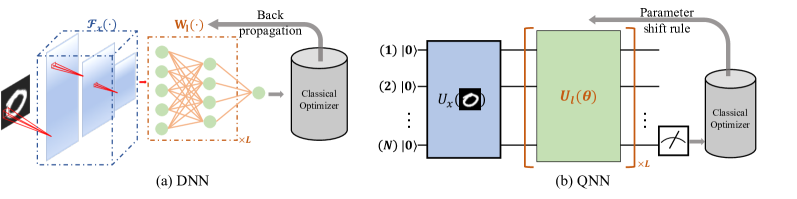
Among the first rigorous learnability analyses of quantum neural networks under realistic noise. We derived learnability bounds and proved that anything a quantum statistical-query model can learn, a parametrized quantum circuit can learn too — so near-term devices keep their generalization edge. PRX Quantum, 2021. [paper]
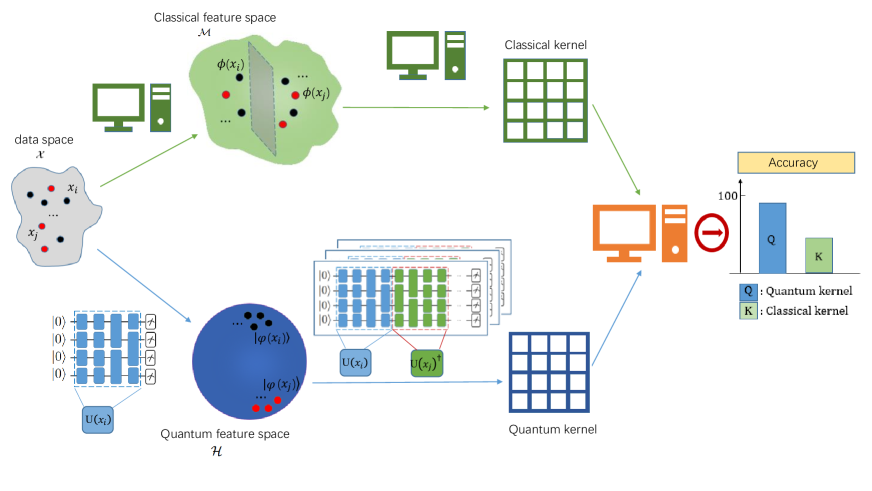
One of the first studies to pin down when quantum kernels truly help on near-term hardware — and the conditions under which that advantage quietly disappears. Quantum kernels are among the most hardware-friendly ways to put a quantum computer to work on a learning task. Quantum, 2021. [paper]
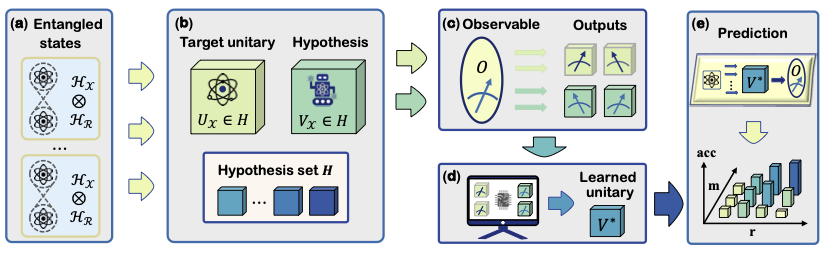
The first work to uncover a transition in the value of entangled data. Is more entanglement in your training data always better? No — we found a tipping point: with many measurements it helps, but when measurements are scarce (the realistic case today) it actively hurts. A practical recipe for spending limited quantum resources wisely. [paper]
② AI for Quantum Science
Quantum hardware is scarce, noisy, and expensive to run. Can we train AI to be a fast, cheap stand-in — predicting what a quantum computer would do, characterizing how it behaves, and squeezing more out of every shot? This is where AI gives quantum its biggest practical boost, and it's where most of my work sits right now. 🚀
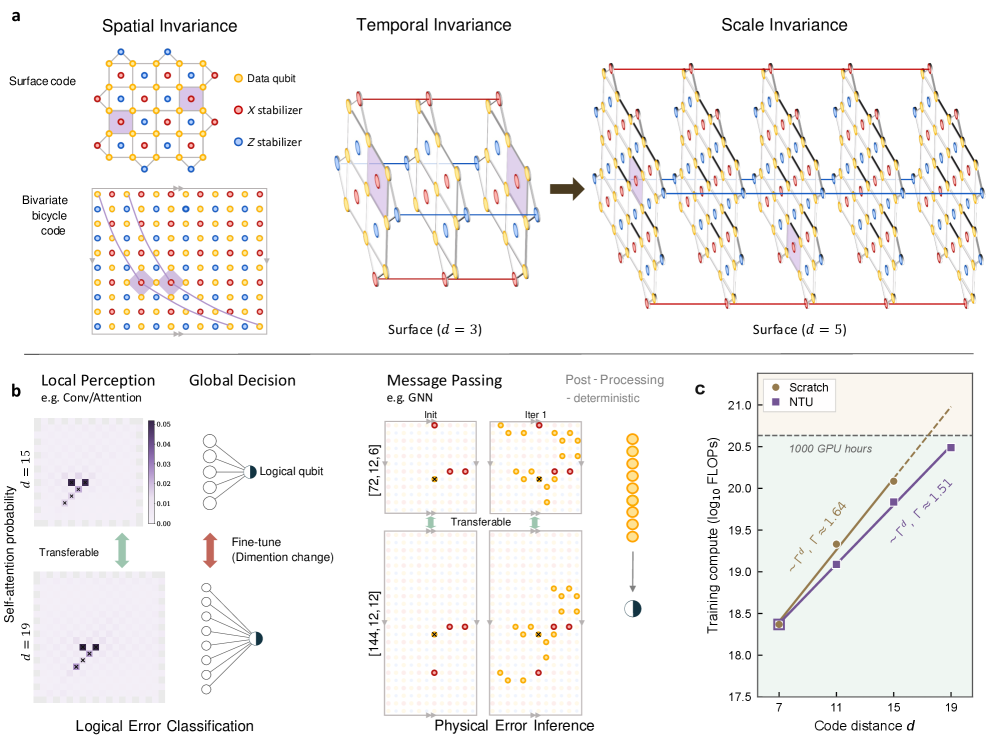
The first foundation decoder that transfers across quantum codes and distances. Training a fresh neural decoder for every code is wasteful — our transformer-based decoders reuse the shared algebraic structure between codes, beating existing decoders on both surface codes and bivariate-bicycle codes and charting a scalable route to fault-tolerant quantum computing. 2026. [paper]
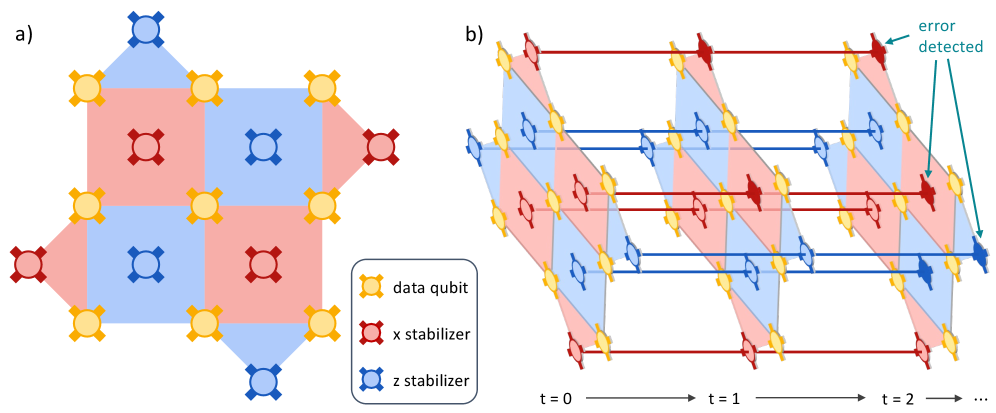
One of the first works to critically re-examine what neural decoders should — and shouldn't — do in quantum error correction, and where they genuinely help. We also show how to mitigate hardware errors sample-efficiently with learning surrogates. ICML 2026. [decoders] [error mitigation]
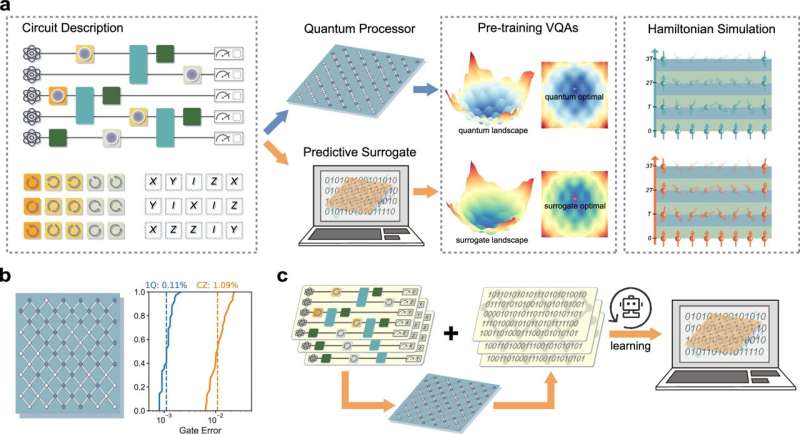
The first predictive surrogates that scale to large quantum processors with rigorous guarantees. After learning from a tiny number of real runs, they forecast the outcomes of brand-new quantum computations using only a classical computer — cutting measurement overhead by 99.97% while staying accurate even as the chip grows. Featured by MIT Technology Review and Phys.org. Nature Communications, 2026. [paper]
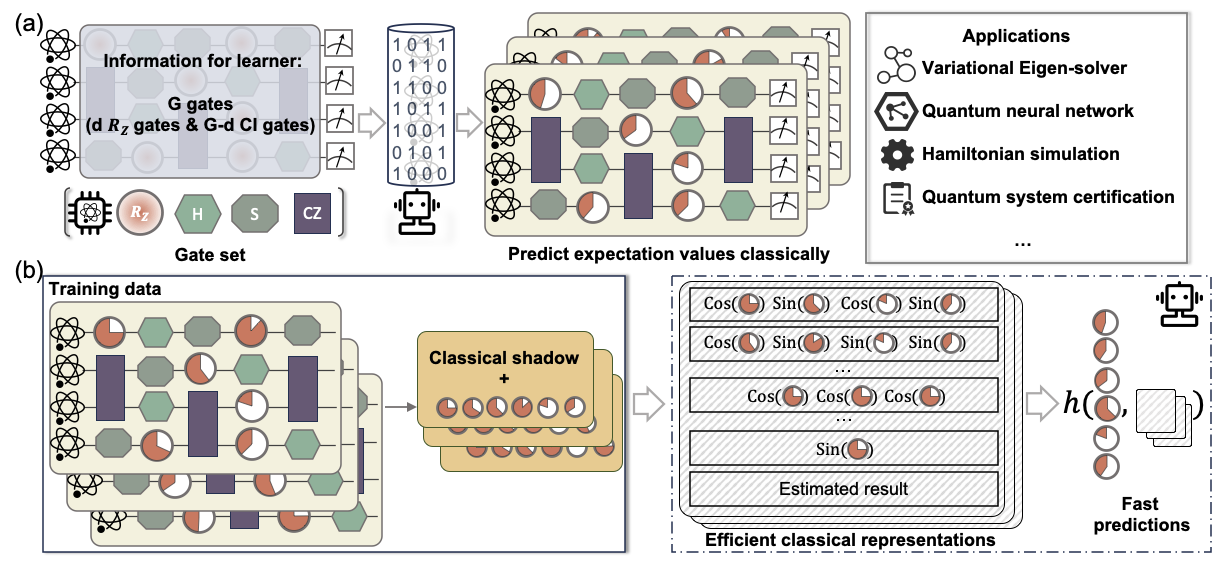
The first efficient classical learner for the linear properties of bounded-gate quantum circuits. For circuits with only a handful of "hard" (non-Clifford) gates, our model (powered by classical shadows) predicts their behavior at a cost that doesn't explode as you add qubits — a building block for cheaper algorithm design, error correction, and certification. Nature Communications, 2025. [paper]
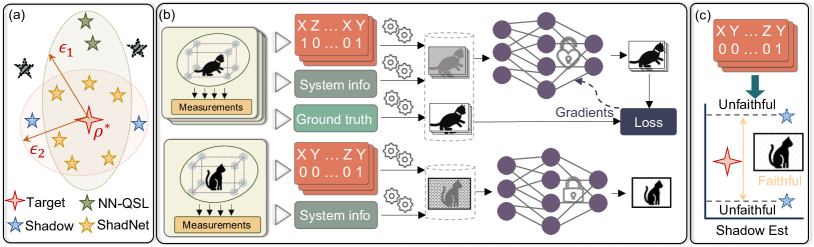
One of the first data-centric frameworks to fuse classical shadows with neural networks for quantum system learning. Train offline, then predict the properties of unseen systems from just a few measurements — demonstrated up to 60 qubits, with the memory efficiency of shadows built in. [paper]
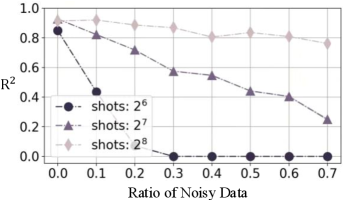
Among the first to show that AI-generated synthetic data can sharpen quantum property estimation. Good training data is hard to get on quantum hardware — so we generate it, and the synthetic labels markedly improve the learning models. NeurIPS 2025. [paper]

One of the first systematic reassessments of what deep learning should really do for large-scale quantum systems — what works, what over-promises, and why. ICML 2025. [paper]
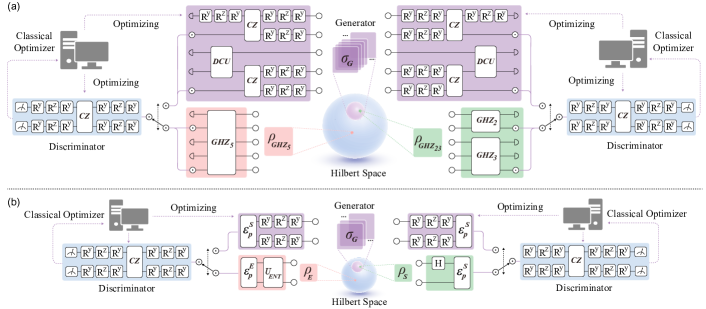
The first scheme to certify entanglement with a quantum adversarial solver. We recast entanglement detection as a two-player game solved by a parametrized circuit — an efficient poly(N) protocol needing only a simple yes/no measurement, demonstrated on real linear-optics hardware. Physical Review Letters, 2022. [paper]
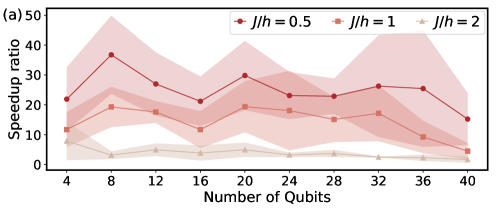
Among the first to scale variational quantum algorithms by learning what to freeze and how to optimize. TITAN learns which parameters to freeze, letting variational quantum eigensolvers reach far larger systems; PALQO is a physics-informed model that accelerates large-scale quantum optimization. Both at NeurIPS 2025. [TITAN] [PALQO]
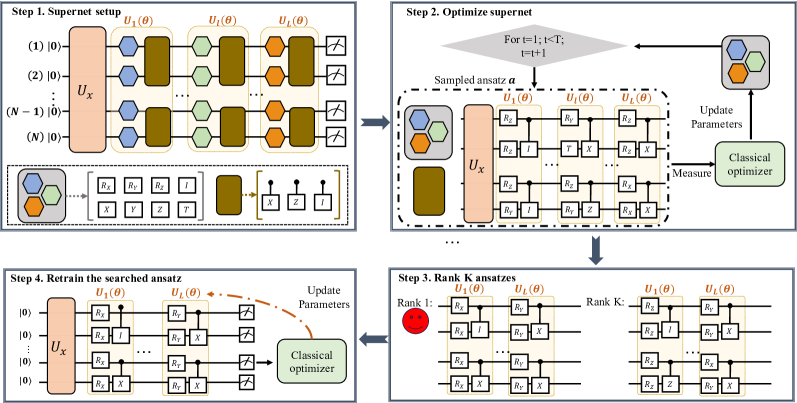
One of the first frameworks to bring neural-architecture-search ideas to quantum circuits. Instead of hand-designing a circuit gate by gate, we automatically search for the best-performing one for a task — improving the trainability and efficiency of variational quantum algorithms. [paper]
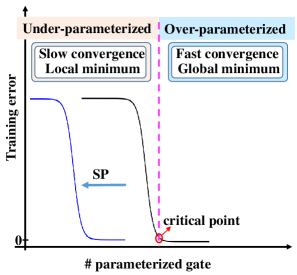
The first to prove why symmetric circuits train better — and turn it into a pruning algorithm. Symmetric pruning automatically extracts a compact, trainable circuit from an over-parametrized one, easing barren plateaus and cutting the depth needed to train. ICLR 2023. [paper]

KQFuzz is among the first to use large language models to fuzz-test quantum libraries and surface hidden faults (ASE 2026), while AQER is a scalable, efficient data loader for digital quantum computers (ICLR 2026). [AQER]
③ Quantum for AI
The flip side of the coin: can quantum computers make machine learning itself better? Here I design quantum models for real learning tasks — generating images, defending classifiers from attacks, guaranteeing privacy — and probe where a genuine quantum edge might show up. ⚛️

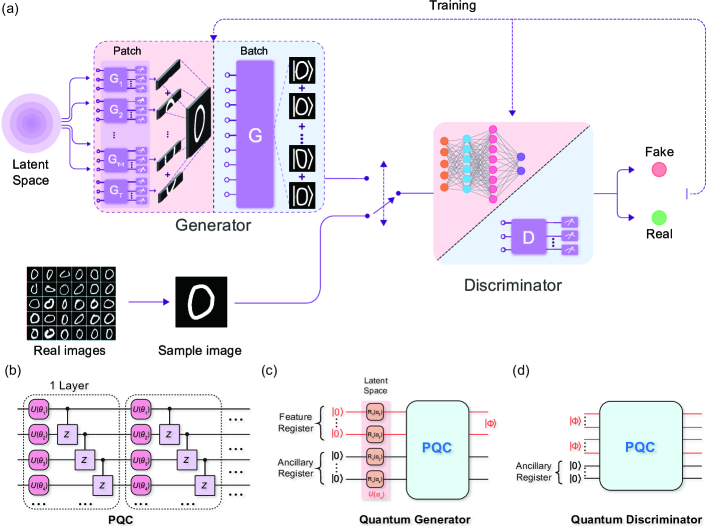
One of the first experiments to run a quantum GAN on real superconducting hardware and generate recognizable images — an early, concrete demonstration of quantum generative learning. Phys. Rev. Applied, 2021. [paper]
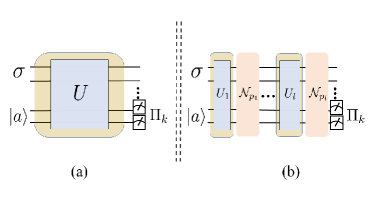
The first to show that quantum noise can protect classifiers against adversarial attacks. Counterintuitively, the very noise that plagues quantum devices acts as a built-in shield — a rare case where hardware imperfection becomes an advantage. Phys. Rev. Research, 2021. [paper]
Among the first to bring differential privacy into quantum learning. We designed a quantum differentially private estimator for sparse regression with rigorous privacy guarantees, protecting the data a quantum model trains on. IEEE Transactions on Information Theory, 2022. [paper]
One of the first quantum learning schemes built directly on Grover search. By reframing classification as a search problem, most existing quantum classifiers slot right in — with a provable speedup in the query model. New Journal of Physics, 2021. [paper]
📚 Surveys & Book

Springer Nature, 2025
A from-scratch tour of the field, for newcomers and practitioners alike. [book]
Nature Reviews Physics, 2026
How modern AI is reshaping the way we describe, measure, and understand quantum systems. [paper]
IEEE Trans. Pattern Analysis & Machine Intelligence (TPAMI), 2023
A survey of quantum models for generative learning. [paper]